GenAI-Driven Pokémon Go Companion App: Augmenting onboarding experience with RAG
Abstract: This article introduces an E2E application aimed at enhancing the onboarding experience for new Pokémon Go players through a Langchain-framework-based app that integrates with the OpenAI API, leveraging GPT-4’s capabilities. Central to the application is a GenAI-powered Pokémon index, designed as a companion to reduce new user friction and deepen understanding of the game’s universe. By employing a Retrieval-Augmented Generation system with FAISS, Meta’s vector database, the app ensures information retrieval. With a workflow controlled entirely by a LLM, it offers functionalities such as Pokémon information, squad creation, and defense strategies. The app is aiming to improve user retention, widen the game’s demographic reach, and ease the learning curve. The project shows the potential of linking AI with mobile gaming to craft intuitive, engaging platforms to improve user retention and game understanding among newcomers.
Important: Any views, material or statements expressed are mines and not those of my employer, read the disclaimer to learn more.1
⚠️ Introduction to problem
Introducing a GenAI companion app for guiding new users in Pokémon Go makes a lot of sense when we look at the challenges the community faces. Pokémon Go isn’t just a game; it’s a phenomenon that has captured the attention of millions, combining engaging gameplay with real-world exploration.
In 2023, the game boasted 145 million MAU, showcasing its massive appeal. Despite experiencing a dip in revenue in 2022, dropping to $0.77 billion from its peak, Pokémon Go continues to draw in a vast number of players as mentioned by Mansoor Iqbal.
One key aspect of Pokémon Go’s success is its broad and diverse player base. The demographics are varied, with a significant number of young adults playing the game. Additionally, there’s a pretty balanced gender distribution among players, with 45.1% male and 54.9% female according to Player Counter. This diversity speaks volumes about the game’s ability to attract and engage a wide range of people.
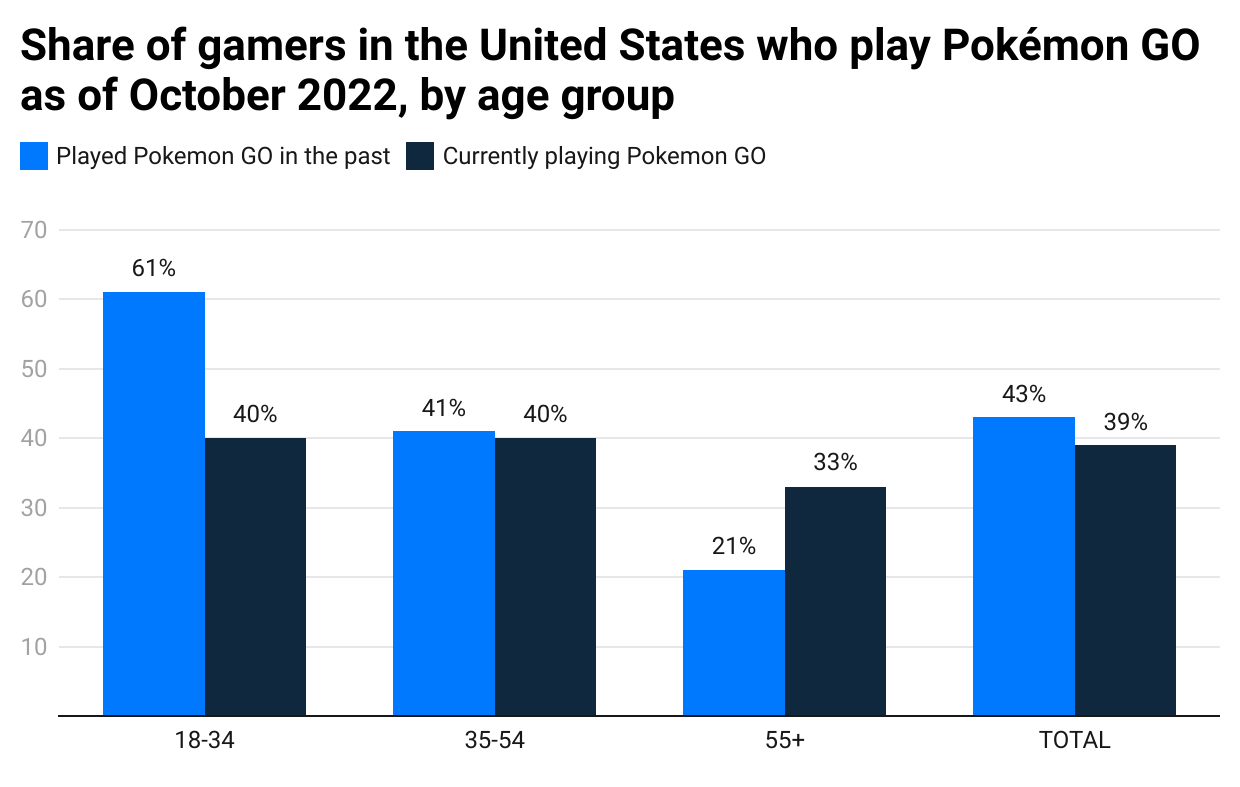
The latest graph from Statista reveals an intriguing trend: a significant drop in the application’s usage among users aged between 18 and 54, who previously used the app but now do not. Conversely, users above 55 have shown the opposite behavior, demonstrating increased engagement. This information is particularly crucial given that most users are young adults; however, daily engagement is something that should be measured using at least D1 to D7 Retention for a clearer diagnosis.
Understanding DAU behavior is vital for a game generating $4 million in daily revenue, as reported by SensorTower. However, the graph does not suggest that Niantic may need to do more to help new users learn the game and keep them engaged.
Drawing on these insights, it’s clear that a GenAI companion app could fulfill several key roles:
- Onboarding and Education: This function would help newcomers grasp the fundamental aspects of the game, including basic rules and strategic approaches. By demystifying the initial learning curve, the app ensures that new players can quickly become competent and enjoy their gaming experience.
- Adaptation Support: As games evolve, introducing new features or temporary changes can sometimes confuse even the most experienced players. Here, the GenAI companion app steps in to offer timely updates and tutorials, helping players adapt and continue to enjoy the game without interruption.
- Guidance for New Joiners in the Pokemon Saga: Specifically tailored to those new to the Pokemon series, this feature of the app would act as a QA support system. It addresses common queries and challenges that newcomers face, ensuring they feel supported as they embark on their Pokemon journey.
Hypothesis
Following the perspective provided by the previous data, and given the limited availability of real data, it will be assumed as a base hypothesis that the creation of a complementary application will serve to substantially improve the key roles mentioned in the following hypothesis.
- The companion app will significantly support onboarding, and offer adaptive assistance, thereby facilitating a smoother introduction for new members to the Pokémon series.
Now, under the premise that there must be enough statistical evidence to reject the null hypothesis, the following technical article will be explained, which will show the architecture and development of this GenAI application, but is not intended to be used as professional advice or consultation.
Potential Stakeholders
- Programmers: Tasked with developing the technical infrastructure for GenAI integration, augmented reality features, and ensuring smooth app functionality across devices.
- Testers: Essential for identifying bugs and ensuring the GenAI interactions, with augmented reality features work as intended across various devices and real-world scenarios.
- Publisher: Interested in the market potential of combining Pokémon Go’s popularity with cutting-edge GenAI technology to attract new players and retain existing ones.
Note: To facilitate the understanding of the roles of the development team, I invite you to take a look at this diagram that I designed.
⚠️ Audience message: If the theoretical and technical details of this article are not of your interest, feel free to jump directly to the Application Workflow section.
📥 About the model
This GenAI app uses OpenAI’s GPT-4 by default for its advanced NLP capabilities. However, understanding the various needs of users, I incorporated a feature that allows easy replacement of the AI model through a simple parameter adjustment, during the initialization of the OpenAI Chatbot instance.
The customization option ensures that users can align application performance with their specific requirements, balancing factors such as computational efficiency, cost, and task specificity, this one can be modified in the global_conf.yml file of the repository.
🏗️ Architecture components
To grasp the application workflow, it’s important to first familiarize with the components that make up the architecture and understand their functionalities. To aid in this explanation, let’s refer to the following architecture diagram, which provides a comprehensive overview.
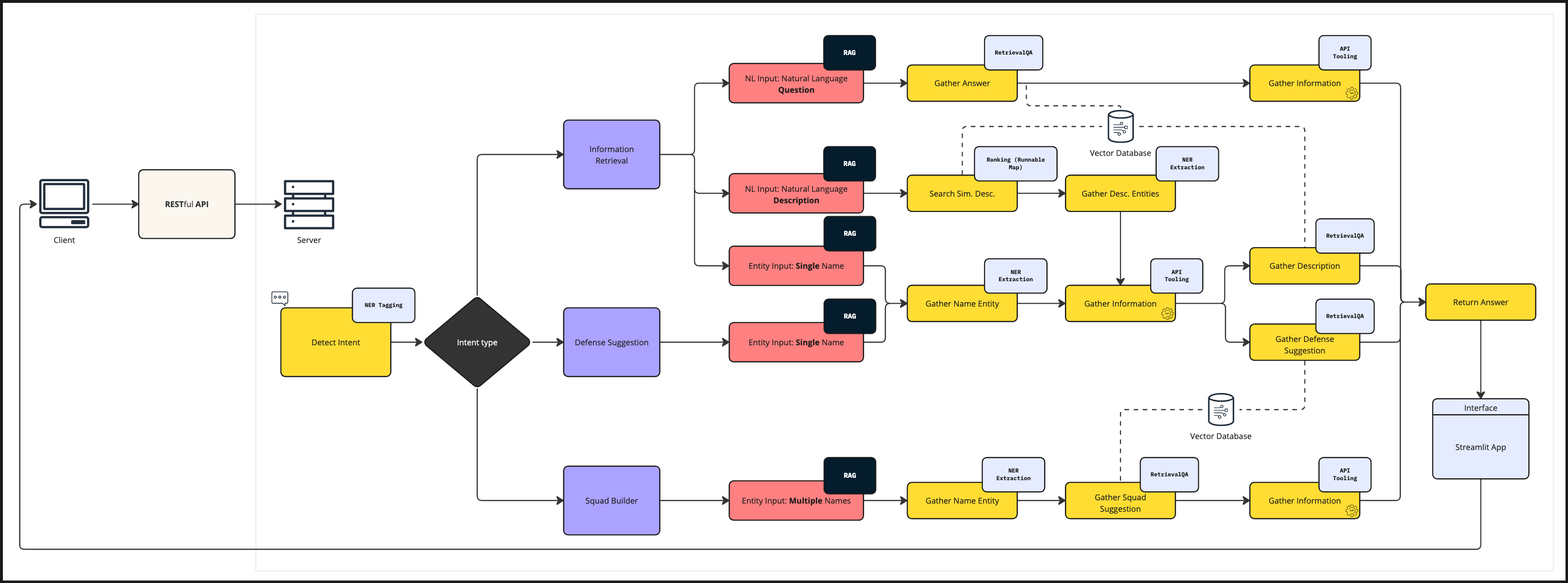
📦 Setup Loader
When initializing the application or invoking the LLM, the first step is crucial but might not be showed in the last diagram. This step ensures the consistent return of the same LLM model instance, along with essential components like the environment configuration, the logger, a callback handler for agent’s monitoring, and the prompt library.
This consistency is achieved through the Singleton design pattern. Essentially, this pattern ensures that every call to SetupLoader() results in the return of the identical instance configuration. By doing so, it guarantees the model’s settings, such as temperature and other configurations remain uniform and constant across the server.
|
|
It’s worth noting there’s a special parameter, new_model, designed for scenarios where a new instance creation is explicitly required. This option adds flexibility for use cases that demand refreshing the LLM settings.
📦 Tagging
Components: Detect Intent
When examining the diagram’s structure, we can identify a step that plays a pivotal role: evaluating user input and deciding the subsequent path for redirecting requests or questions. All this will happen on the first step of the IntentHandler.
This task is achieved through the implementation of a Tagging strategy, which is built upon a base Pydantic model. Put simply, this process is similar to a Named Entity Recognition system. However, a difference is the limitation to a predefined set of categories for text classification.
|
|
The intent_type can be classified include:
defense_suggestion: Prompt mentions that an unknown Pokémon has appeared and the user needs a suggestion to use a Pokémon against it. The user must provide the name of the Pokémon as part of the input.information_request: The user wants to know more about a Pokémon. In the input, the user must provide a request for information on one or multiple entities.squad_build: The user wants to build a squad of Pokémon based on the opponent’s Pokémon types. The user must provide a list of Pokémon names as part of the input.
And, the intent_structure, which describe the syntactic composition of the text, can be classified in:
pokemon_names: Sentence with the name of one or more Pokémon explicitly mentioned in the text with an expressed request.natural_language_description: Sentence with a description of a Pokémon in natural language without explicitly mentioning the name of the Pokémon with the intention of guessing what the Pokémon is.natural_language_question: Sentence with a question about the Pokémon whose name is mentioned explicitly, asking for a specific attribute(s) belonging to the Pokémon entity.
Note that intent_parser helps structure the LLM response, meaning that the output will be consistently returned as a Pydantic object, and based on this attributes, the system will define where to redirect the request.
📦 Named Entity Recognition (NER)
Components: Gather Name Entity | Gather Desc. Entities
Also known as Multiple Extraction approach, this phase involves a general procedure that incorporates Pydantic models, which will be used for various intents presented in the architecture. In this specific instance, a Pydantic model functions as an entity object.
It is characterized by defined attributes that are essential for the Named Entity Recognition extraction process. Let’s refer to the following code example:
|
|
Here, the PokemonEntity will represent a Pokemon named in the prompt, and name is the identifiable entity attribute with its respective data type. However, the real challenge arises when we introduce multiple names into the prompt. This is where the PokemonEntityList comes into play.
The advantage of the PokemonEntityList is quite significant. It allows for the addition of more attributes to the PokemonEntity class seamlessly. This feature ensures that the LLM can accurately determine which entity each attribute belongs to.
To put this into perspective, consider a scenario where the prompt given is “Charizard and Treecko are fire and grass type Pokémon respectively”. The output structure generated from this prompt is both efficient and logical, demonstrating the system’s capability to assign entities, simply great:
|
|
This way, a chain is created and invoked by converting the Pydantic class into an OpenAI function.
|
|
📦 API Tooling
Components: Gather Information
Langchain provides two solutions to augment the output of LLMs through two primary methods: “Agents” and “Chains.” The “Agents” method involves calling an agent that intelligently selects and utilizes the necessary tools as often as needed to fulfill a request. This process is automatic, leveraging the agent’s ability to determine the most suitable tool for the task at hand.
On the other hand, “Chains” offers a more tailored approach, which is particularly beneficial for our specific needs. By employing “Chains”, we can make a customized Pokemon API wrapper that functions as an OpenAI tool.
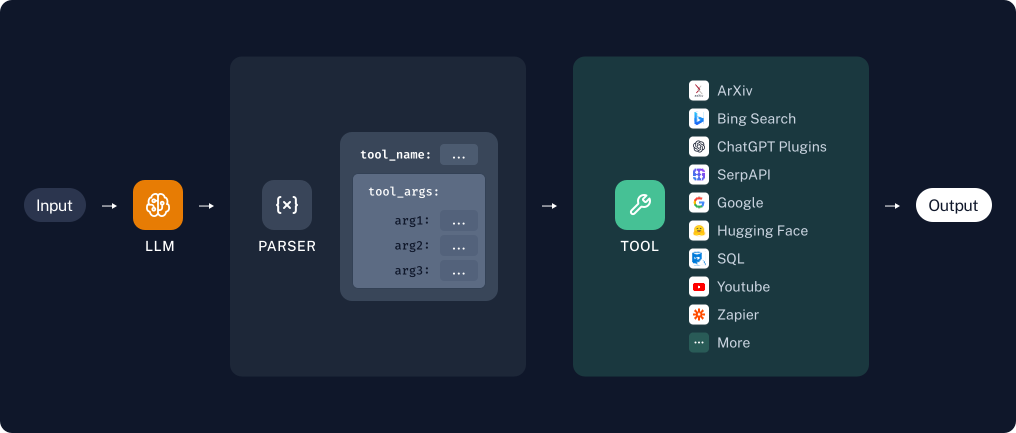
In the previous illustration, we outlined a process flow. Here, we can go deeper into each step:
- Input: The system begins by reading the natural language input provided by the user.
- Parser: Next in the interpretation, the system employs a parser to analyze the type of input received. This analysis is essential for identifying the most appropriate tool within the model that is suited for processing the given input. The parser acts as a bridge, connecting the input with its relevant processing tool.
- Create Arguments: Once the appropriate tool is identified, the system then proceeds to formulate the necessary arguments required to utilize the tool effectively. These arguments, along with the names of the selected tools, are temporarily stored in an output.
- Tool Mapping: In the final step, the prepared arguments are forwarded to the actual function designated for the task. The system then executes the function, extracting the outputs generated.
Following this structured approach, the API tool code is designed as shown below:
|
|
📦 Retrieval-Augmented Generation - Retrieval QA
Components: Gather Answer | Search Sim. Desc | Gather Description | Gather Defense Suggestion | Gather Squad Suggestion
For better understanding, first let’s break down this kind of component into two key parts, focusing on how we handle data and answer questions using Large Language Models:
- Retrieval-Augmented Generation (RAG): This method uses a two-step process. First, it finds relevant information files (e.g.: Pokemon Wiki as PDF) related to the input. Then, it combines this information with the original request to create a response. This approach is great for generating detailed and enhanced descriptions.
- RetrievalQA: This strategy is all about answering questions. It searches for and retrieves information related to the question from a knowledge base (e.g.: Vector Store). Then, it uses this information to either directly provide an answer or to create one. In such a system, when a question is asked, the model retrieves relevant documents or passages from a knowledge base and then either extracts or generates an answer based on this chunk of information.
☑️ Vector Store
To implement these methods, we’re using a tool Vector Store FAISS, created by Meta AI Research. Faiss is designed for quickly finding information that’s similar to your search query, even in huge databases. We chose to use FAISS for its features, explained simply:
- It can search multiple vectors simultaneously, even without a GPU enabled, thanks to its great multithreading capabilities.
- It finds not just the closest match but also the second closest, third closest, and so on, using a Euclidean distance (L2) to search for its similarity.
- It trades precision for speed, e.g.: give an incorrect result 10% of the time with a method that’s 10x faster or uses 10x less memory.
- It saves data on the disk instead of using RAM.
- It works with binary vectors, which are simpler than the usual floating-point vectors.
More details can be found at the Meta’s official wiki.
☑️ Process
After loading the files using Langchain Document Loaders.
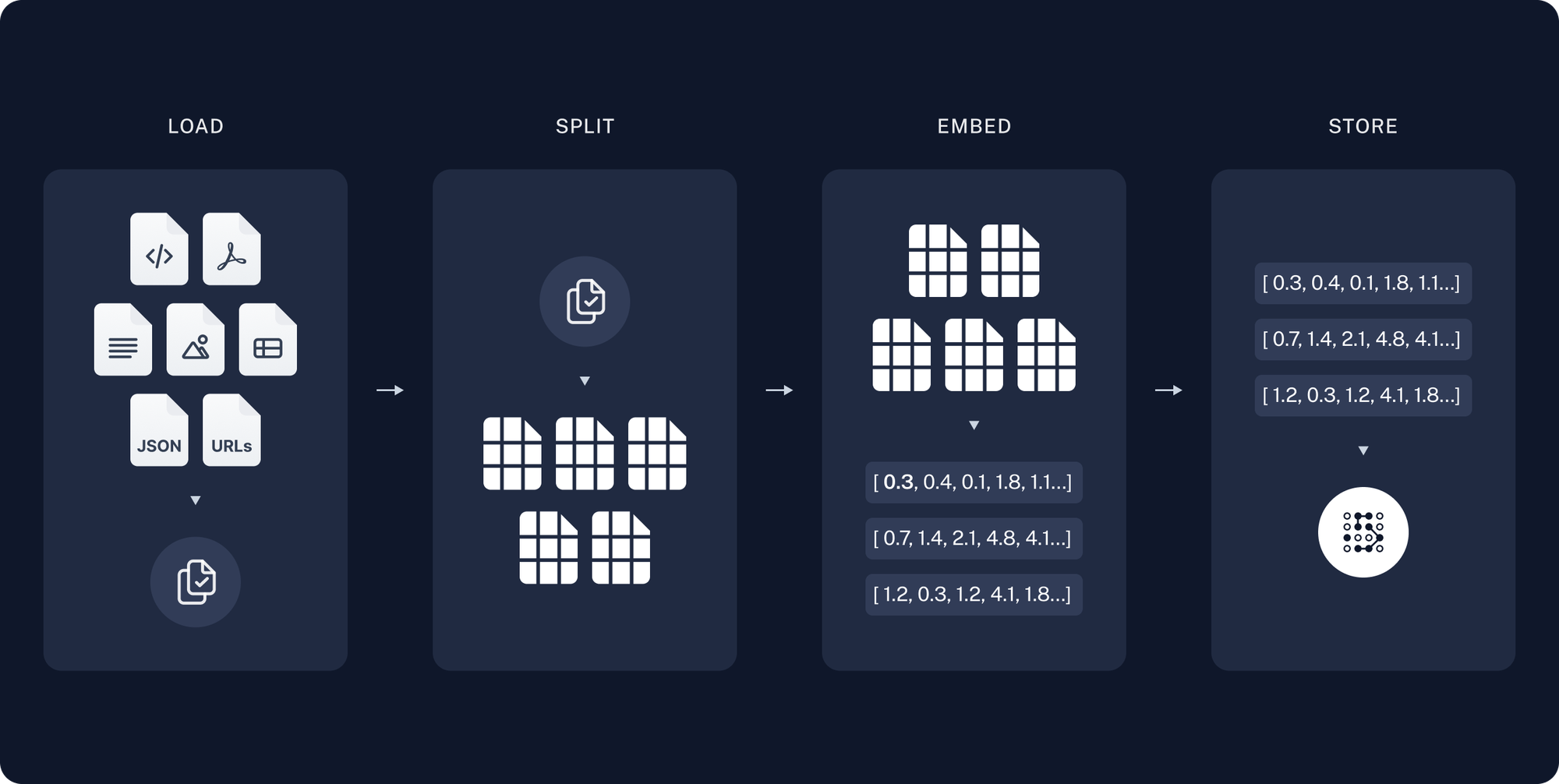
Split:
- The first steps is to define the splitting strategy using Text Splitters. The decision between recursive or character-based text splitting is a preprocessing step to divide the document into manageable chunks. This is important because FAISS operates on vectors, and the text must first be converted into a numerical format (vector representation) that FAISS can work with. The splitting helps in managing document size and ensuring each chunk is meaningful for the vectorization process.
Embed:
Here are two process relevant to this step:
- Vectorization: While FAISS itself doesn’t handle the text-to-vector conversion, this step is essential for preparing data for similarity search. The choice of embedding method (like
OpenAIEmbeddings) significantly affects the quality of the search results, as it determines how well semantic similarities are captured in the vector space. Embeddings are high-dimensional vectors that represent the semantic content of the text. Each word, sentence, or document is mapped to a point in a high-dimensional space, where the distance between points corresponds to semantic similarity. - Indexing: involves creating a structured representation of the files that allows for similarity searches.
Store:
- Saving the vector store locally means storing the indexed representation of the document chunks. This allows for persistent access to the indexed data for future similarity searches without needing to re-process the original documents. We chose to keep this index in the same repository (
.faiss&.pkl) for simplicity, but it’s also possible to store it in a artifact repository manager like JFrog.
|
|
☑️ Retrieval Chain
We had the option to utilize a vector store with either a map-reduce approach or a parallel similarity search based on the prompt’s context.
In our specific case, the PDF contains a wiki-style format with one Pokemon per page. This format enables the Recursive Text Splitter to efficiently separate and index each subject (Pokemon), each of which is unique. Therefore, we require only a single chunk per Pokemon || Question.
- A map-reduce approach is not suitable for our needs. Although it can identify and summarize groups of similar chunks, as described by Perplexity.ai, we are only interested in extracting a single, relevant chunk.
- Consequently, we have decided to base our entire architecture on a RunnableParallel mechanism. This will allow us to make context searches and assign questions to each document in parallel.
|
|
📦 API endpoints
The entire conditional process is consolidated into a single API endpoint, distinct from the UI’s URL, ensuring the UI’s independence from the computational resources required for the IntentHandler process. The infrastructure relies on FastAPI, with a Pydantic schema handling the I/O object.
|
|
To separately test the API independently, start the server with the command make api_server, and then access the Swagger UI.
📦 User Interface
The UI dynamically adapts based on the response format, utilizing a custom template generator. This generator feeds data into the Streamlit UI, tailoring the display to match both the intent type and the syntactic structure of the user’s prompt. The core of this functionality is a large Python @dataclass, which serves as the response template generator and is accessible for reference.
⚡ Application Workflow
The application simplifies setting up and deploying APIs built with FastAPI. The README file includes a series of Make targets with a range of functions, from environment setup to API configuration and UI deployment. This section focuses on explaining the workflow and functionalities, rather than the technical details behind them.
The E2E process is guided by the prompt’s intent (type) and syntax (structure). Using these, the application with assistance from the LLM, directs the workflow to the appropriate tools. If the response is not recognized, it is redirected to GPT-4’s general knowledge, with a banner citing the source on the final response.
UI Features
The first step involves familiarizing the user with the response feature. After launching the UI on a local port, a side panel appears on the left (see image below, labeled as 1), featuring a toggle for activating or deactivating JSON mode, set to off by default. This mode presents responses in JSON format (labeled as 2), facilitating debugging or analysis of the response’s target within the “Intent Handler” workflow or “Response Formatter” (core components). This by default is set to False.
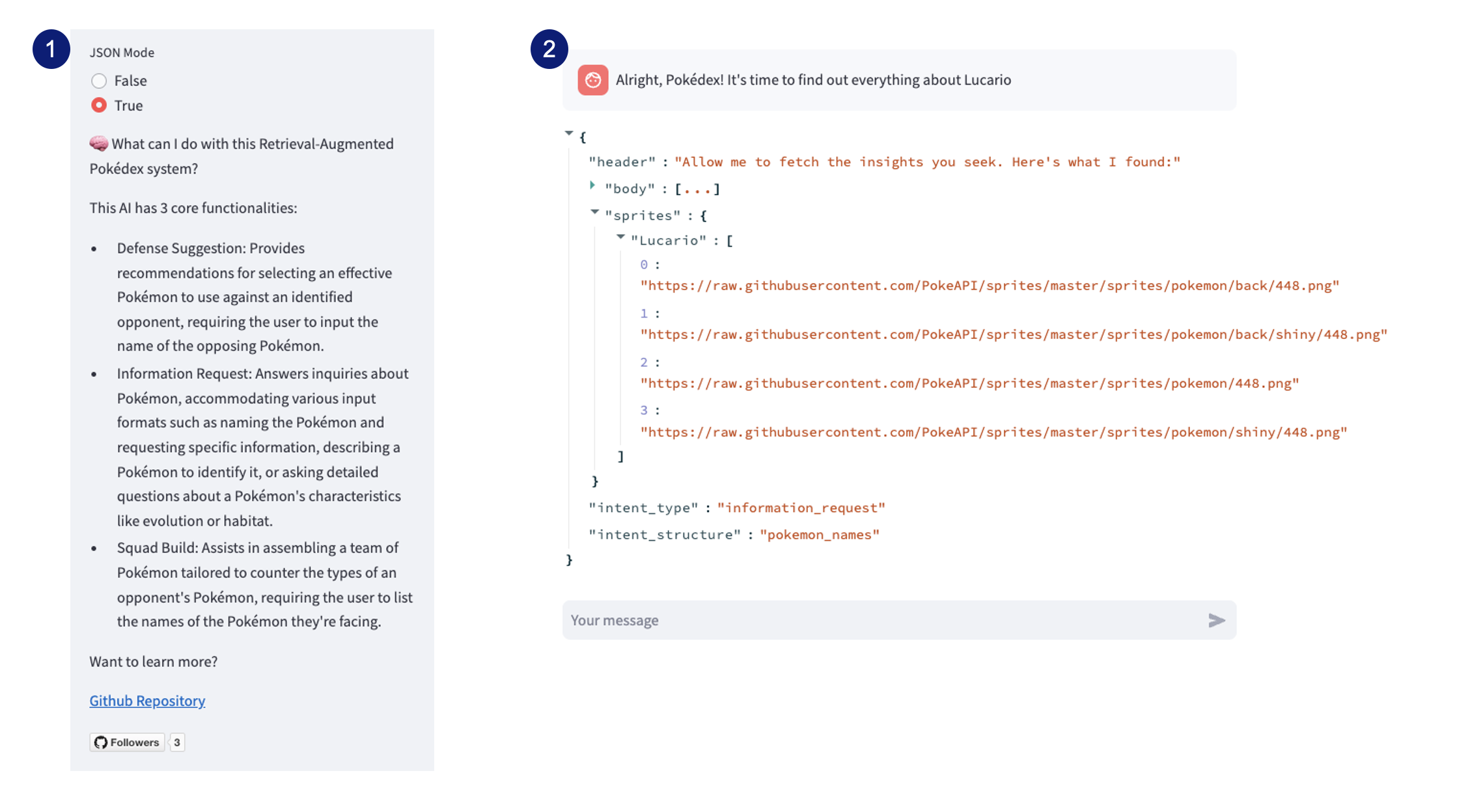
Once we’ve defined the output format, the next step involves sending a request to the API. However, the API’s response can vary significantly based on the type of intent. As previously discussed in the “Tagging” component, the Intent Handler can detect multiple combinations of intents. We will detail each of these intents in the following section:
Information Retrieval Intent
This intent primarily seeks information on one or more Pokémon, with the process adapting to the syntactic structure of the request.
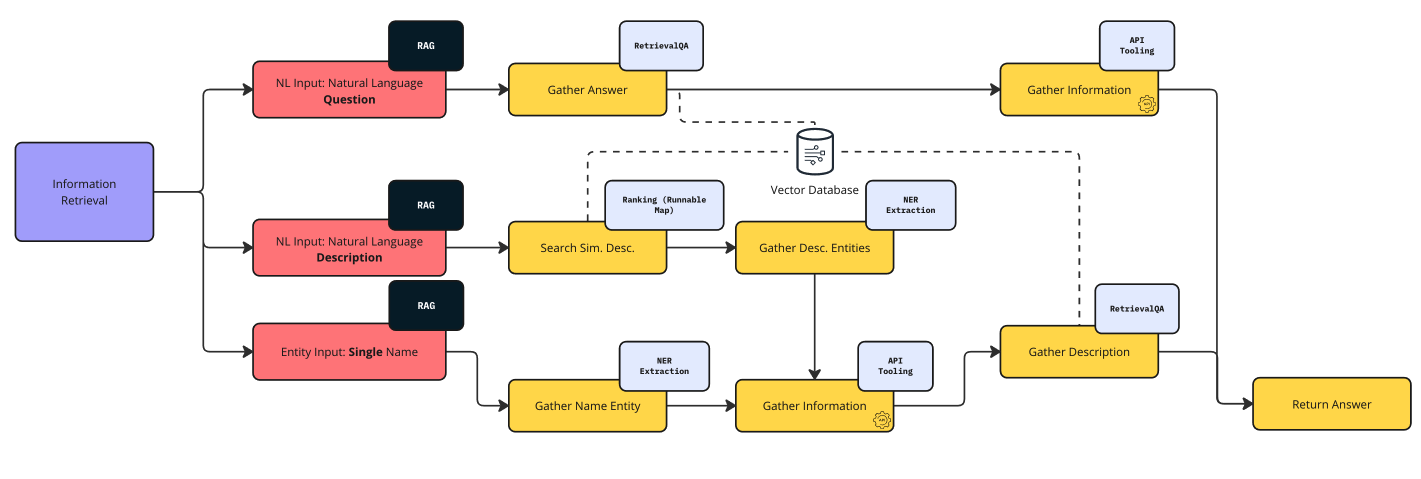
There are 3 types of syntactic structures:
- Natural Language Question: A question about a Pokémon initiates a RetrievalQA process through the Vector Database to find an answer. The Pokémon’s name is identified as an entity, triggering an API wrapper request to deliver the final response.
E.g.: “Do you know in what kind of habitats I can find a Psyduck?”. - Natural Language Description: This involves inputting a description used at identifying a Pokémon. The process selects the most similar document chunk from the Vector Database, including the Pokémon’s name. Next, a NER process identifies the Pokémon name within the text, using this entity to make an API request. This retrieves information and structures a description from the Vector Database to formulate the answer.
E.g.: “Can you guess which Pokémon is a dual-type Grass/Poison Pokémon known for the plant bulb on its back, which grows into a large plant as it evolves”. - Single Named Entity: The simplest approach, it directly uses NER to detect the Pokémon’s name. This entity then prompts an API request to obtain information, which is used to form a structured description from the Vector Database to provide the answer.
E.g.: “Alright, Pokédex! It’s time to find out everything about Snorlax and Pikachu!”.
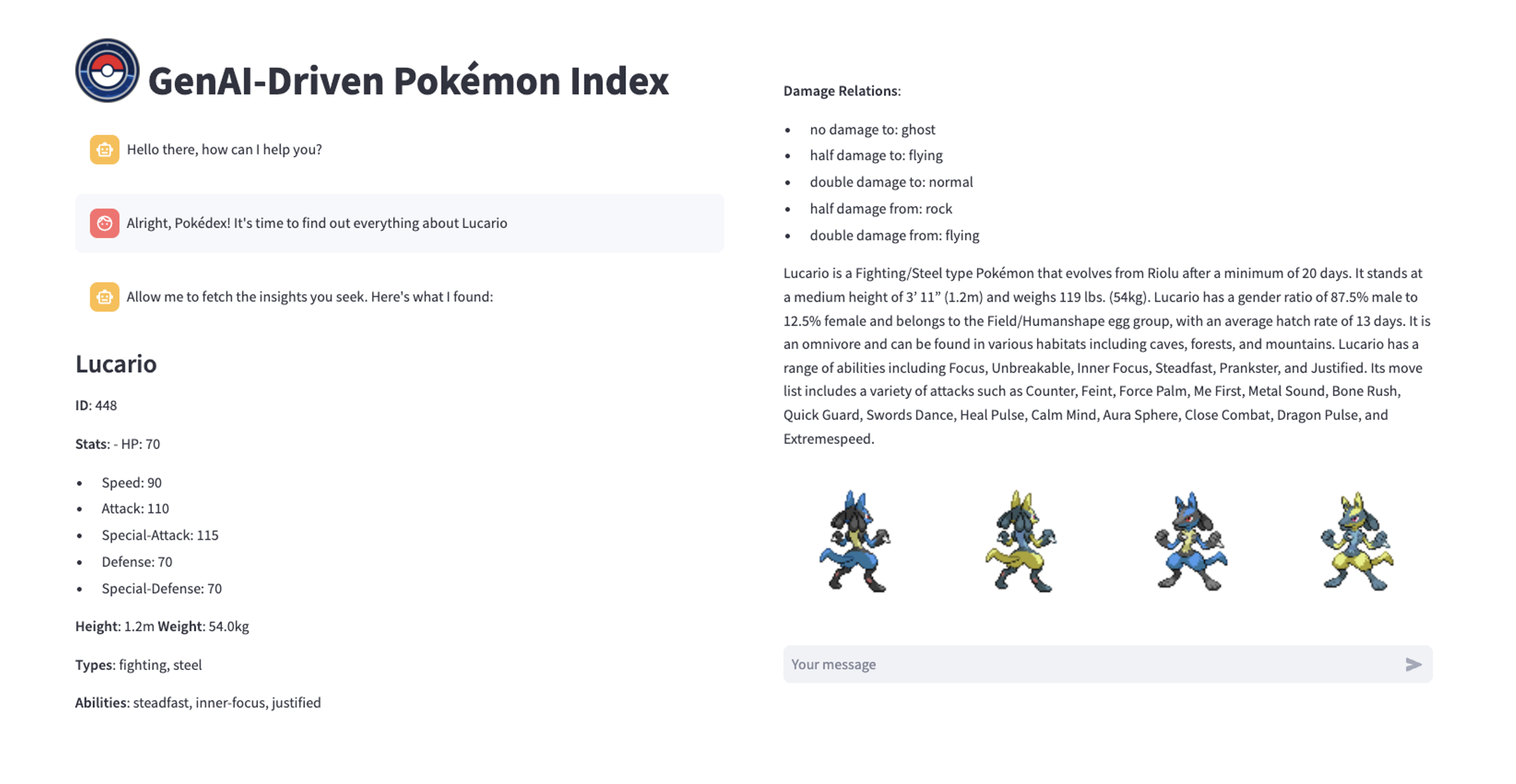
The expected structured output look as follows.
Defense Suggestion Intent
This intent aims to offer players advice on defending against Pokémon, useful for capturing Pokémon or winning battles against other players.

When a user encounters an unidentified Pokémon and requests a recommendation for a counter Pokémon, they must specify the name of the Pokémon. E.g.: “I stumbled upon a wild Grovyle lounging in the park! Which Pokemon should I choose for an epic battle to defeat it?”.
- Initially, we identify the Pokémon’s name as a Named Entity using a Pydantic Class for extraction. This entity is then processed by the system, which aligns the input schema with the corresponding API entry.
- Subsequently, we create an embedding request that highlights the opposing Pokémon’s vulnerabilities based on its type.
- Leveraging this information, the LLM augment the response using Vector Database context to suggest the most effective Pokémon to use in battle.
The expected structured output look as follows.

Squad Builder Intent
This intent facilitates the creation of a Pokémon squad tailored to counter the types of an opponent’s Pokémon, in simple words it builds a squad. Users must input a list of the opponent’s Pokémon names as part of the prompt. E.g.: “Time to challenge the Fire Gym Leader! He’s got a tough team with a Ninetales and Combusken, but I need your help to build a squad”.

- Initially, the language model identifies each Pokémon in the opponent’s squad and creates a vulnerability template for each, similar to the approach in the “defensive” intent.
- Subsequently, it identifies suggested Pokémon entities and submits them to an API, which returns a structured response for each entity.
The expected structured output look as follows.

Sprites Design
Last but not least, each of the answers has a structure with the same format, which provides as part of the API wrapper the sprites of the classic designs of the series.
🗒️ Final thoughts & takeaways
What can the stakeholders understand and take in consideration?
Implementing a GenAI-driven chatbot for user onboarding is beneficial, but it’s important to also focus on the quality of supplementary resources, such as wikis. These play a significant role in enhancing response augmentation process. Additionally, scalability demands may require evaluating various Vector Database services, including Pinecone, elasticsearch, Cassandra, among others.
To assess the viability of this approach, it’s essential to first evaluate the token consumption for all LLM calls related to each intent.
What could the stakeholders do to take action?
Prior to adopting such an approach, a thorough analysis of user needs is crucial. Examining user retention from D1 to D7 across different cohorts (e.g.: demography-based), supported by a robust segmentation strategy, provides valuable insights into user behavior and needs.
The current integration serves as a preliminary demonstration. Developing a companion app will require addressing a distinct set of integration requirements.
ℹ️ Additional Information
Here you have a list of preferred materials for you to explore if you’re interested in similar topics:
- Related Content
— About Langchain.
— OpenAI models Pricing page.
— Meta’s FAISS tutorials.
— User Segmentation Strategies by IronSource from Unity.
— Pokémon Go release notes by Niantic.
- Augmentation Assets
The RetrievalQA system was augmented using an unofficial Tabletop Pokémon Guide. An official resource is suggested to improve response quality and avoid any bias.
-
Article disclaimer: The information presented in this article is solely intended for learning purposes and serves as a tool for the author’s personal development. The content provided reflects the author’s individual perspectives and does not rely on established or experienced methods commonly employed in the field. Please be aware that the practices and methodologies discussed in this article do not represent the opinions or views held by the author’s employer. It is strongly advised not to utilize this article directly as a solution or consultation material. ↩︎